Filter by type:
Filter by tags:

qwopus3.6-27b-coder-compat-mtp
🪐 Qwopus-3.6-27B-Coder
Coder SFT Release
Agentic Coding & Tool-Use Reasoning Model Fine-Tuned on Qwopus3.6-27B-v2
🧬 Trace Inversion & Negentropy
🧠 27B Dense Model
⚡ Agentic Coding
🛠️ Tool Calling & Agent
🏆 SWE-bench Verified: 67.0% (off-thinking)
💡 What is Qwopus-3.6-27B-Coder?
🪐 Qwopus-3.6-27B-Coder is a reasoning-enhanced agentic coding model built on top of Qwopus3.6-27B-v2. It inherits the powerful reasoning foundation of the v2 base — which achieved 87.43% MMLU-Pro and 75.25% SWE-bench Verified — and further specializes it for agentic code generation, structured tool calling, debugging, and instruction-following in developer workflows. The model is designed to excel at repository-level coding tasks, multi-turn tool orchestration, and complex logical reasoning under realistic agent environments.
🧩 Agentic Coding
Optimized for repository-level coding, debugging, patch generation, and structured multi-step development workflows.
🛠️ Tool Calling
Learns from real agent trajectories with tool definitions, tool calls, and environment feedback for robust multi-turn execution.
...
Repository: localaiLicense: apache-2.0
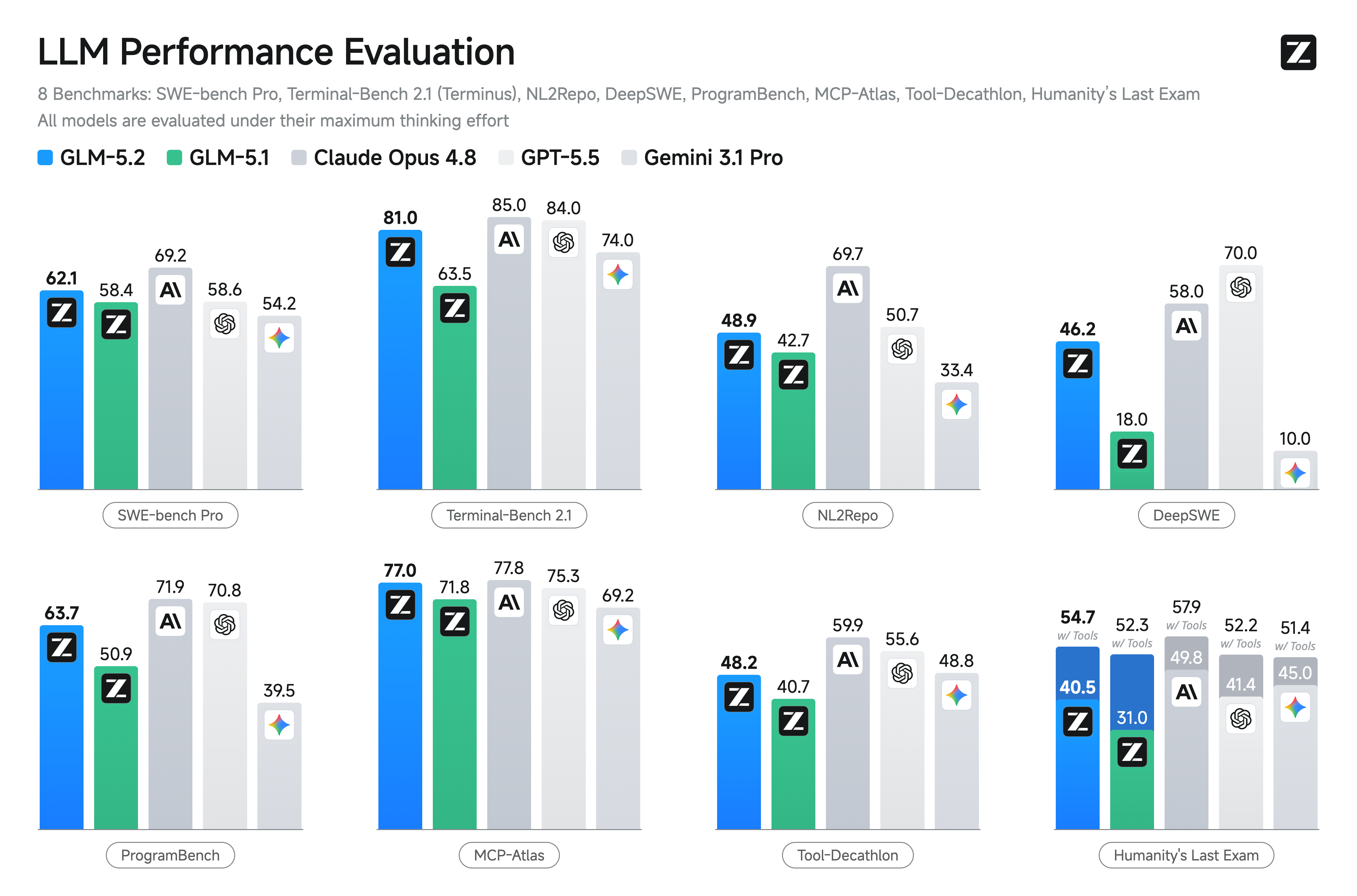
glm-5.2
# GLM-5.2
👋 Join our WeChat or Discord community.
📖 Check out the GLM-5.2 blog and GLM-5 Technical report.
📍 Use GLM-5.2 API services on Z.ai API Platform.
🔜 Try GLM-5.2 here.
[Paper]
[GitHub]
## Introduction
We're introducing GLM-5.2, our latest flagship model for long-horizon tasks. It marks a substantial leap in long-horizon task capability over its predecessor GLM-5.1 and, for the first time, delivers that capability on a **solid 1M-token context**. GLM-5.2's new capabilities include:
- **Solid 1M Context:** A solid 1M-token context that stably sustains long-horizon work
- **Advanced Coding with Flexible Effort**: Stronger coding capabilities with multiple thinking effort levels to balance performance and latency
- **Improved Architecture**: We propose IndexShare, which reuses the same indexer across every four sparse attention layers, reducing per-token FLOPs by 2.9× at a 1M context length. We also improve GLM-5.2’s MTP layer for speculative decoding, increasing the acceptance length by up to 20%
- **Pure Open**: An MIT open-source license — no regional limits, technical access without borders
## Benchmark
## Serve GLM-5.2 Locally
...
Repository: localaiLicense: mit

qwen3.6-35b-a3b-nvfp4-mtp
# Qwen3.6-35B-A3B
[](https://chat.qwen.ai)
> [!Note]
> This repository contains model weights and configuration files for the post-trained model in the Hugging Face Transformers format.
>
> These artifacts are compatible with Hugging Face Transformers, vLLM, SGLang, KTransformers, etc.
Following the February release of the Qwen3.5 series, we're pleased to share the first open-weight variant of Qwen3.6. Built on direct feedback from the community, Qwen3.6 prioritizes stability and real-world utility, offering developers a more intuitive, responsive, and genuinely productive coding experience.
## Qwen3.6 Highlights
This release delivers substantial upgrades, particularly in
- **Agentic Coding:** the model now handles frontend workflows and repository-level reasoning with greater fluency and precision.
- **Thinking Preservation:** we've introduced a new option to retain reasoning context from historical messages, streamlining iterative development and reducing overhead.
For more details, please refer to our blog post Qwen3.6-35B-A3B.
## Model Overview
...
Repository: localai

qwopus3.6-27b-v2-mtp-nvfp4
🪐 Qwopus3.6-27B-v2-MTP
MTP Release
Multi-Token Prediction reasoning model fine-tuned from Qwen3.6-27B
🧬 Trace Inversion & Negentropy
🧠 27B Parameters
⚡ Speculative Decoding
🛠️ Coding / DevOps / Math
💡 What is Qwopus3.6-27B-v2-MTP?
🪐 Qwopus3.6-27B-v2-MTP is a speed-oriented reasoning release built on top of Qwen3.6-27B. It keeps the Qwopus line's focus on reconstructed reasoning traces, coding discipline, DevOps procedures, and mathematical derivations, while adding Multi-Token Prediction for faster generation. The goal is simple: preserve the depth and structure of a 27B reasoning model while making real interactive use noticeably faster.
⚡ MTP DecodingAuxiliary future-token prediction improves throughput on long reasoning, code, math, and strict-format prompts.
🧩 Structured ReasoningInherits the Qwopus training recipe built around reconstructed step-by-step reasoning trajectories.
🧪 GB10 TestedValidated on a 30-question local benchmark across Logic, Coding, DevOps, Math, and Edge tasks.
🚀 Practical SpeedDesigned for workflows where strong answers matter, but waiting several extra minutes per task does not.
...
Repository: localai
qwopus3.6-27b-coder-mtp-nvfp4
🪐 Qwopus-3.6-27B-Coder
Coder SFT Release
Agentic Coding & Tool-Use Reasoning Model Fine-Tuned on Qwopus3.6-27B-v2
🧬 Trace Inversion & Negentropy
🧠 27B Dense Model
⚡ Agentic Coding
🛠️ Tool Calling & Agent
🏆 SWE-bench Verified: 67.0% (off-thinking)
💡 What is Qwopus-3.6-27B-Coder?
🪐 Qwopus-3.6-27B-Coder is a reasoning-enhanced agentic coding model built on top of Qwopus3.6-27B-v2. It inherits the powerful reasoning foundation of the v2 base — which achieved 87.43% MMLU-Pro (300ex) and 75.25% SWE-bench Verified — and further specializes it for agentic code generation, structured tool calling, debugging, and instruction-following in developer workflows. The model is designed to excel at repository-level coding tasks, multi-turn tool orchestration, and complex logical reasoning under realistic agent environments.
🧩 Agentic Coding
Optimized for repository-level coding, debugging, patch generation, and structured multi-step development workflows.
🛠️ Tool Calling
Learns from real agent trajectories with tool definitions, tool calls, and environment feedback for robust multi-turn execution.
...
Repository: localai

qwen3.6-27b-nvfp4-mtp
# Qwen3.6-27B
[](https://chat.qwen.ai)
> [!Note]
> This repository contains model weights and configuration files for the post-trained model in the Hugging Face Transformers format.
>
> These artifacts are compatible with Hugging Face Transformers, vLLM, SGLang, KTransformers, etc.
Following the February release of the Qwen3.5 series, we're pleased to share the first open-weight variant of Qwen3.6. Built on direct feedback from the community, Qwen3.6 prioritizes stability and real-world utility, offering developers a more intuitive, responsive, and genuinely productive coding experience.
## Qwen3.6 Highlights
This release delivers substantial upgrades, particularly in
- **Agentic Coding:** the model now handles frontend workflows and repository-level reasoning with greater fluency and precision.
- **Thinking Preservation:** we've introduced a new option to retain reasoning context from historical messages, streamlining iterative development and reducing overhead.
For more details, please refer to our blog post Qwen3.6-27B.
## Model Overview
...
Repository: localai
qwen3.6-27b-mtp-pi-tune
# Qwen3.6-27B
[](https://chat.qwen.ai)
> [!Note]
> This repository contains model weights and configuration files for the post-trained model in the Hugging Face Transformers format.
>
> These artifacts are compatible with Hugging Face Transformers, vLLM, SGLang, KTransformers, etc.
Following the February release of the Qwen3.5 series, we're pleased to share the first open-weight variant of Qwen3.6. Built on direct feedback from the community, Qwen3.6 prioritizes stability and real-world utility, offering developers a more intuitive, responsive, and genuinely productive coding experience.
## Qwen3.6 Highlights
This release delivers substantial upgrades, particularly in
- **Agentic Coding:** the model now handles frontend workflows and repository-level reasoning with greater fluency and precision.
- **Thinking Preservation:** we've introduced a new option to retain reasoning context from historical messages, streamlining iterative development and reducing overhead.
For more details, please refer to our blog post Qwen3.6-27B.
## Model Overview
...
Repository: localaiLicense: apache-2.0
qwopus3.6-27b-coder-mtp
🪐 Qwopus3.6-27B-v2
SFT Release
Reasoning-Enhanced Dense Language Model Fine-Tuned on Qwen3.6-27B
🧬 Trace Inversion & Negentropy
🧠 27B Parameters
🔥 3-Stage Curriculum SFT
🛠️ Vision & Tool-use Support
💡 What is Qwopus3.6-27B-v2?
🪐 Qwopus3.6-27B-v2 is a reasoning-enhanced dense language model built on top of Qwen3.6-27B. By leveraging a multi-stage curriculum learning pipeline and augmented with Trace Inversion datasets (claude-opus-4.6/4.7-traceInversion), it reverse-engineers the compressed "Reasoning Bubbles" of commercial LLMs into structured, step-by-step synthetic reasoning traces, successfully eliminating logical shortcuts and knowledge fractures.
🧩 Structured Reasoning
Injects reconstructed deep CoT chains to eliminate logical shortcuts via Trace Inversion.
🪶 Style Consistency
Enforces strict constraints on the format and convergence of <think> tags.
🔁 Distillation Alignment
Ensures high-quality cross-source SFT data alignment to narrow the capacity gap.
⚡ RL Scalability
Sets up a stable formatting pipeline optimized for downstream Reinforcement Learning (RL).
## 💡 1. Base Model, Training Library & Cooperation
...
Repository: localaiLicense: apache-2.0

qwopus3.5-9b-coder-mtp
# 🌟 Qwopus3.5-9B-v3.5
## 💡 Model Overview & v3.5 Design
Qwopus3.5-9B-v3.5 is a **data-scaled continuation** of the Qwopus3.5-9B-v3 model.
The training data in v3.5 is expanded to cover a broader range of domains, including mathematics, programming, puzzle-solving, multilingual dialogue, instruction-following, multi-turn interactions, and STEM-related tasks.
Qwopus3.5-9B-v3.5 is a reasoning-enhanced model based on **Qwen3.5-9B**, designed for:
- 🧩 Structured reasoning
- 🔧 Tool-augmented workflows
- 🔁 Multi-step agentic tasks
- ⚡ Token-efficient inference
Compared with Qwopus3.5-9B-v3, **3.5 version does not introduce a new architecture, RL stage, or template redesign**.
This version is trained with approximately **2× more SFT data**.
## 🎯 Motivation & Generalization Insight
The motivation behind v3.5 comes from a simple observation:
> This work is motivated by the hypothesis that scaling high-quality SFT data may further enhance the generalization ability of large language models.
In earlier Qwopus3.5 experiments, structured reasoning was observed to improve both **accuracy and efficiency**:
...
Repository: localaiLicense: apache-2.0
qwopus3.6-27b-v2-mtp
🪐 Qwopus3.6-27B-v2-MTP
MTP Release
Multi-Token Prediction reasoning model fine-tuned from Qwen3.6-27B
🧬 Trace Inversion & Negentropy
🧠 27B Parameters
⚡ Speculative Decoding
🛠️ Coding / DevOps / Math
💡 What is Qwopus3.6-27B-v2-MTP?
🪐 Qwopus3.6-27B-v2-MTP is a speed-oriented reasoning release built on top of Qwen3.6-27B. It keeps the Qwopus line's focus on reconstructed reasoning traces, coding discipline, DevOps procedures, and mathematical derivations, while adding Multi-Token Prediction for faster generation. The goal is simple: preserve the depth and structure of a 27B reasoning model while making real interactive use noticeably faster.
⚡ MTP DecodingAuxiliary future-token prediction improves throughput on long reasoning, code, math, and strict-format prompts.
🧩 Structured ReasoningInherits the Qwopus training recipe built around reconstructed step-by-step reasoning trajectories.
🧪 GB10 TestedValidated on a 30-question local benchmark across Logic, Coding, DevOps, Math, and Edge tasks.
🚀 Practical SpeedDesigned for workflows where strong answers matter, but waiting several extra minutes per task does not.
...
Repository: localaiLicense: apache-2.0
qwopus3.6-35b-a3b-v1
# Qwen3.6-35B-A3B
[](https://chat.qwen.ai)
> [!Note]
> This repository contains model weights and configuration files for the post-trained model in the Hugging Face Transformers format.
>
> These artifacts are compatible with Hugging Face Transformers, vLLM, SGLang, KTransformers, etc.
Following the February release of the Qwen3.5 series, we're pleased to share the first open-weight variant of Qwen3.6. Built on direct feedback from the community, Qwen3.6 prioritizes stability and real-world utility, offering developers a more intuitive, responsive, and genuinely productive coding experience.
## Qwen3.6 Highlights
This release delivers substantial upgrades, particularly in
- **Agentic Coding:** the model now handles frontend workflows and repository-level reasoning with greater fluency and precision.
- **Thinking Preservation:** we've introduced a new option to retain reasoning context from historical messages, streamlining iterative development and reducing overhead.
For more details, please refer to our blog post Qwen3.6-35B-A3B.
## Model Overview
...
Repository: localaiLicense: apache-2.0

qwen3.5-9b-deepseek-v4-flash
# Qwen3.5-9B
[](https://chat.qwen.ai)
> [!Note]
> This repository contains model weights and configuration files for the post-trained model in the Hugging Face Transformers format.
>
> These artifacts are compatible with Hugging Face Transformers, vLLM, SGLang, KTransformers, etc.
Over recent months, we have intensified our focus on developing foundation models that deliver exceptional utility and performance. Qwen3.5 represents a significant leap forward, integrating breakthroughs in multimodal learning, architectural efficiency, reinforcement learning scale, and global accessibility to empower developers and enterprises with unprecedented capability and efficiency.
## Qwen3.5 Highlights
Qwen3.5 features the following enhancement:
- **Unified Vision-Language Foundation**: Early fusion training on multimodal tokens achieves cross-generational parity with Qwen3 and outperforms Qwen3-VL models across reasoning, coding, agents, and visual understanding benchmarks.
- **Efficient Hybrid Architecture**: Gated Delta Networks combined with sparse Mixture-of-Experts deliver high-throughput inference with minimal latency and cost overhead.
...
Repository: localaiLicense: apache-2.0

chroma1-hd
Chroma1-HD is an 8.9B-parameter text-to-image foundation model derived from FLUX.1-schnell with reduced parameter count via architectural optimizations. Designed as a base for creators, researchers, and downstream fine-tuning. Recommended inference: 40 steps, CFG 3.0, bfloat16.
Repository: localaiLicense: apache-2.0
qwopus3.6-27b-v1-preview
# Qwen3.6-27B
[](https://chat.qwen.ai)
> [!Note]
> This repository contains model weights and configuration files for the post-trained model in the Hugging Face Transformers format.
>
> These artifacts are compatible with Hugging Face Transformers, vLLM, SGLang, KTransformers, etc.
Following the February release of the Qwen3.5 series, we're pleased to share the first open-weight variant of Qwen3.6. Built on direct feedback from the community, Qwen3.6 prioritizes stability and real-world utility, offering developers a more intuitive, responsive, and genuinely productive coding experience.
## Qwen3.6 Highlights
This release delivers substantial upgrades, particularly in
- **Agentic Coding:** the model now handles frontend workflows and repository-level reasoning with greater fluency and precision.
- **Thinking Preservation:** we've introduced a new option to retain reasoning context from historical messages, streamlining iterative development and reducing overhead.
For more details, please refer to our blog post Qwen3.6-27B.
## Model Overview
...
Repository: localaiLicense: apache-2.0
qwen3.6-27b
# Qwen3.6-27B
[](https://chat.qwen.ai)
> [!Note]
> This repository contains model weights and configuration files for the post-trained model in the Hugging Face Transformers format.
>
> These artifacts are compatible with Hugging Face Transformers, vLLM, SGLang, KTransformers, etc.
Following the February release of the Qwen3.5 series, we're pleased to share the first open-weight variant of Qwen3.6. Built on direct feedback from the community, Qwen3.6 prioritizes stability and real-world utility, offering developers a more intuitive, responsive, and genuinely productive coding experience.
## Qwen3.6 Highlights
This release delivers substantial upgrades, particularly in
- **Agentic Coding:** the model now handles frontend workflows and repository-level reasoning with greater fluency and precision.
- **Thinking Preservation:** we've introduced a new option to retain reasoning context from historical messages, streamlining iterative development and reducing overhead.
For more details, please refer to our blog post Qwen3.6-27B.
## Model Overview
...
Repository: localaiLicense: apache-2.0
qwen3.6-35b-a3b-claude-4.6-opus-reasoning-distilled
# 🔥 Qwen3.6-35B-A3B-Claude-4.6-Opus-Reasoning-Distilled
A reasoning SFT fine-tune of `Qwen/Qwen3.6-35B-A3B` on chain-of-thought (CoT) distillation mostly sourced from Claude Opus 4.6. The goal is to preserve Qwen3.6's strong agentic coding and reasoning base while nudging the model toward structured Claude Opus-style reasoning traces and more stable long-form problem solving.
The training path is text-only. The Qwen3.6 base architecture includes a vision encoder, but this fine-tuning run did not train on image or video examples.
- **Developed by:** @hesamation
- **Base model:** `Qwen/Qwen3.6-35B-A3B`
- **License:** apache-2.0
This fine-tuning run is inspired by Jackrong/Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled, including the notebook/training workflow style and Claude Opus reasoning-distillation direction.
[](https://x.com/Hesamation) [](https://discord.gg/vtJykN3t)
## Benchmark Results
The MMLU-Pro pass used 70 total questions per model: `--limit 5` across 14 MMLU-Pro subjects. Treat this as a smoke/comparative check, not a release-quality full benchmark.
...
Repository: localaiLicense: apache-2.0
qwen3.6-35b-a3b-apex
# Qwen3.6-35B-A3B
[](https://chat.qwen.ai)
> [!Note]
> This repository contains model weights and configuration files for the post-trained model in the Hugging Face Transformers format.
>
> These artifacts are compatible with Hugging Face Transformers, vLLM, SGLang, KTransformers, etc.
Following the February release of the Qwen3.5 series, we're pleased to share the first open-weight variant of Qwen3.6. Built on direct feedback from the community, Qwen3.6 prioritizes stability and real-world utility, offering developers a more intuitive, responsive, and genuinely productive coding experience.
## Qwen3.6 Highlights
This release delivers substantial upgrades, particularly in
- **Agentic Coding:** the model now handles frontend workflows and repository-level reasoning with greater fluency and precision.
- **Thinking Preservation:** we've introduced a new option to retain reasoning context from historical messages, streamlining iterative development and reducing overhead.
For more details, please refer to our blog post Qwen3.6-35B-A3B.
## Model Overview
...
Repository: localaiLicense: apache-2.0
qwen3.6-35b-a3b
# Qwen3.6-35B-A3B
[](https://chat.qwen.ai)
> [!Note]
> This repository contains model weights and configuration files for the post-trained model in the Hugging Face Transformers format.
>
> These artifacts are compatible with Hugging Face Transformers, vLLM, SGLang, KTransformers, etc.
Following the February release of the Qwen3.5 series, we're pleased to share the first open-weight variant of Qwen3.6. Built on direct feedback from the community, Qwen3.6 prioritizes stability and real-world utility, offering developers a more intuitive, responsive, and genuinely productive coding experience.
## Qwen3.6 Highlights
This release delivers substantial upgrades, particularly in
- **Agentic Coding:** the model now handles frontend workflows and repository-level reasoning with greater fluency and precision.
- **Thinking Preservation:** we've introduced a new option to retain reasoning context from historical messages, streamlining iterative development and reducing overhead.
For more details, please refer to our blog post Qwen3.6-35B-A3B.
## Model Overview
...
Repository: localaiLicense: apache-2.0

qwen_qwen3.5-4b
Qwen3.5-4B is a multimodal LLM with 4 billion parameters, optimized for chat and vision tasks. This GGUF quantized version enables efficient local inference via llama-cpp backend. Supports both text and image input for enhanced conversational capabilities.
Repository: localaiLicense: apache-2.0

qwen3.5-27b-claude-4.6-opus-reasoning-distilled-i1
Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled-i1-GGUF - A GGUF quantized model optimized for local inference. Specialized for reasoning and chain-of-thought tasks. Based on Qwen 3.5 architecture with enhanced language understanding. Available in multiple quantization levels for various hardware requirements. Distilled from Claude-style reasoning models for enhanced logical reasoning capabilities.
Repository: localaiLicense: apache-2.0

qwen3.5-4b-claude-4.6-opus-reasoning-distilled
Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF - A GGUF quantized model optimized for local inference. Specialized for reasoning and chain-of-thought tasks. Based on Qwen 3.5 architecture with enhanced language understanding. Available in multiple quantization levels for various hardware requirements. Distilled from Claude-style reasoning models for enhanced logical reasoning capabilities.
Repository: localaiLicense: apache-2.0
Page 1