Filter by type:
Filter by tags:

ornith-1.0-9b
Repository: localaiLicense: mit
ornith-1.0-35b
Repository: localaiLicense: mit
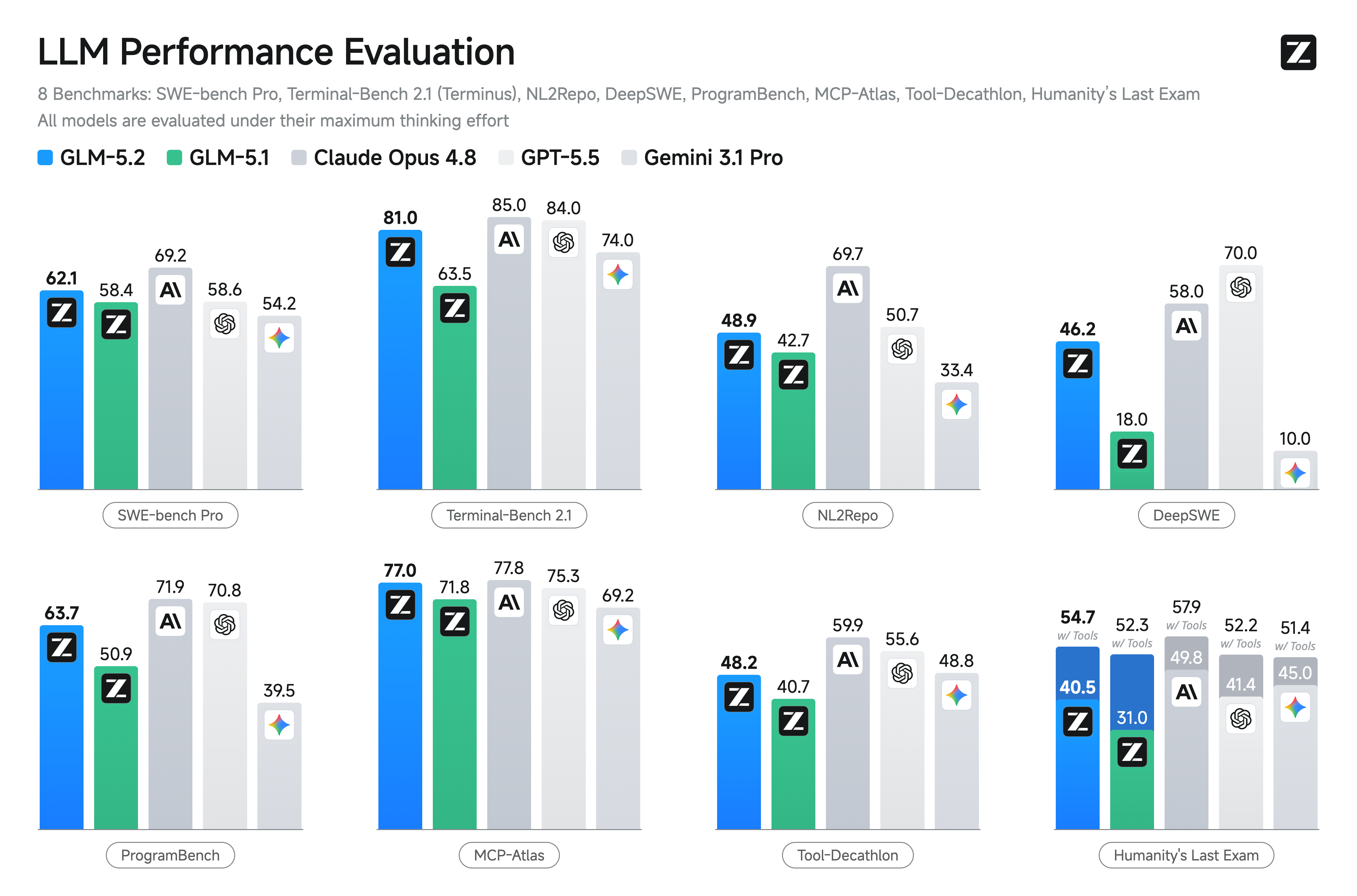
glm-5.2
Repository: localaiLicense: mit
kimi-k2.6
Repository: localaiLicense: modified-mit

gemma-4-26b-a4b-it
Repository: localaiLicense: apache-2.0
gemma-4-e2b-it
Repository: localaiLicense: apache-2.0
gemma-4-e4b-it
Repository: localaiLicense: apache-2.0

nanbeige4.1-3b-q8
Repository: localaiLicense: apache-2.0
nanbeige4.1-3b-q4
Repository: localaiLicense: apache-2.0

qwen3-vl-embedding-8b
Repository: localaiLicense: apache-2.0
qwen3-vl-embedding-2b
Repository: localaiLicense: apache-2.0

opengvlab_internvl3_5-30b-a3b
Repository: localaiLicense: apache-2.0
opengvlab_internvl3_5-30b-a3b-q8_0
Repository: localaiLicense: apache-2.0
opengvlab_internvl3_5-14b-q8_0
Repository: localaiLicense: apache-2.0
opengvlab_internvl3_5-14b
Repository: localaiLicense: apache-2.0
opengvlab_internvl3_5-8b
Repository: localaiLicense: apache-2.0
opengvlab_internvl3_5-8b-q8_0
Repository: localaiLicense: apache-2.0
opengvlab_internvl3_5-4b
Repository: localaiLicense: apache-2.0
opengvlab_internvl3_5-4b-q8_0
Repository: localaiLicense: apache-2.0
opengvlab_internvl3_5-2b
Repository: localaiLicense: apache-2.0
kitten-tts
Repository: localaiLicense: apache-2.0