Filter by type:
Filter by tags:

qwythos-9b-claude-mythos-5-1m
Repository: localaiLicense: apache-2.0
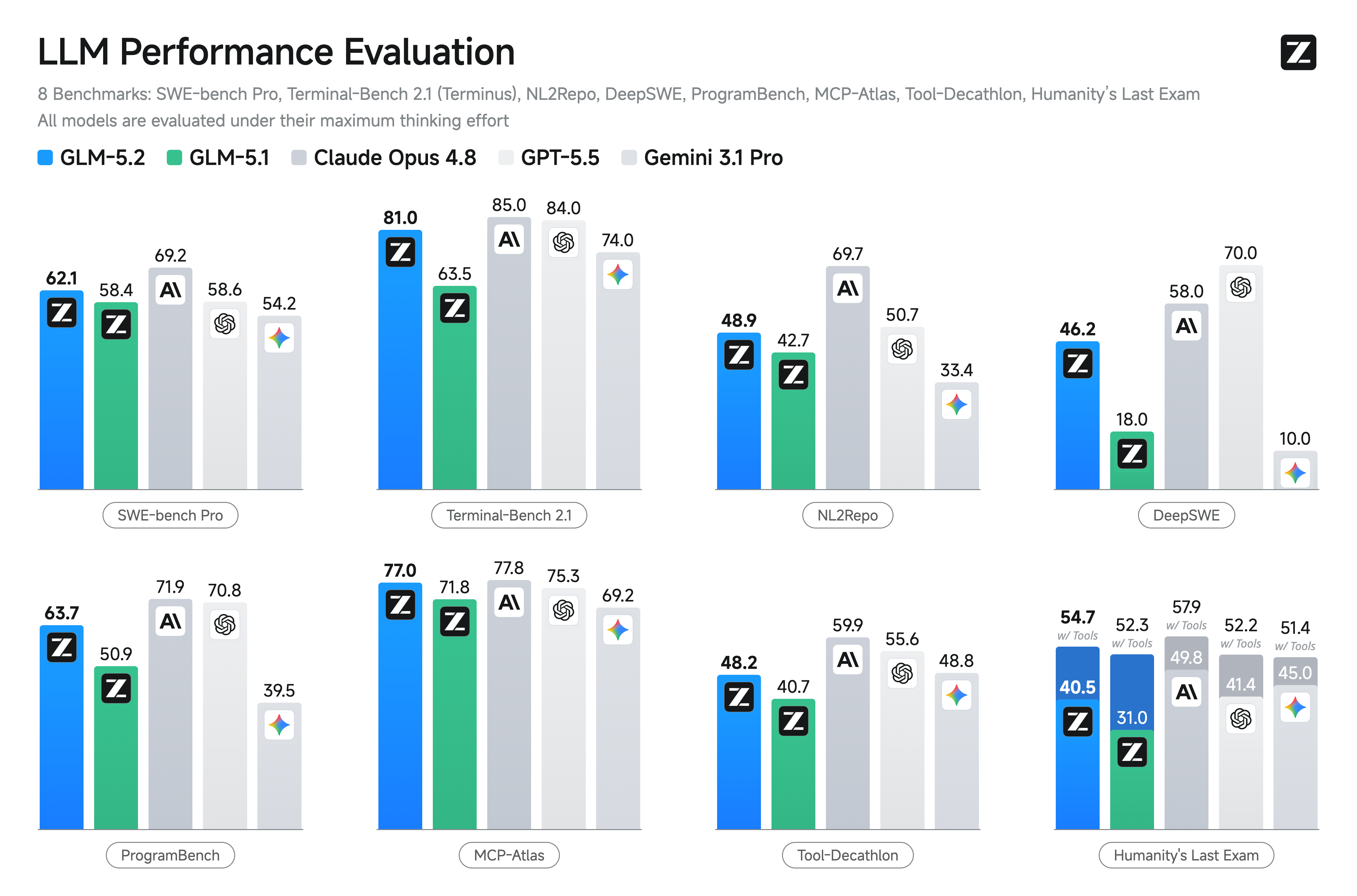
glm-5.2
Repository: localaiLicense: mit

step-3.7-flash
Repository: localaiLicense: apache-2.0

privacy-filter-multilingual
Repository: localaiLicense: apache-2.0
privacy-filter-nemotron
Repository: localaiLicense: apache-2.0

nemotron-3-nano-omni-30b-a3b-reasoning-apex
Repository: localaiLicense: other
kimi-k2.6
Repository: localaiLicense: modified-mit

qwen_qwen3.5-4b
Repository: localaiLicense: apache-2.0

qwen3.5-27b-claude-4.6-opus-reasoning-distilled-i1
Repository: localaiLicense: apache-2.0

qwen3.5-4b-claude-4.6-opus-reasoning-distilled
Repository: localaiLicense: apache-2.0
whisperx-tiny
Repository: localaiLicense: mit

voxcpm-1.5
Repository: localaiLicense: apache-2.0

vllm-omni-qwen3-omni-30b
Repository: localaiLicense: apache-2.0
vllm-omni-qwen3-tts-custom-voice
Repository: localaiLicense: apache-2.0
qwen3-vl-embedding-8b
Repository: localaiLicense: apache-2.0
qwen3-vl-embedding-2b
Repository: localaiLicense: apache-2.0
qwen3-vl-reranker-8b
Repository: localaiLicense: apache-2.0
qwen3-vl-reranker-2b-i1
Repository: localaiLicense: apache-2.0
mistral-nemo-instruct-2407-12b-thinking-m-claude-opus-high-reasoning-i1
Repository: localai
glm-4.5v-i1
Repository: localaiLicense: mit
qwen3-vl-30b-a3b-instruct
Repository: localaiLicense: apache-2.0