Filter by type:
Filter by tags:

qwopus3.6-27b-coder-compat-mtp
🪐 Qwopus-3.6-27B-Coder
Coder SFT Release
Agentic Coding & Tool-Use Reasoning Model Fine-Tuned on Qwopus3.6-27B-v2
🧬 Trace Inversion & Negentropy
🧠 27B Dense Model
⚡ Agentic Coding
🛠️ Tool Calling & Agent
🏆 SWE-bench Verified: 67.0% (off-thinking)
💡 What is Qwopus-3.6-27B-Coder?
🪐 Qwopus-3.6-27B-Coder is a reasoning-enhanced agentic coding model built on top of Qwopus3.6-27B-v2. It inherits the powerful reasoning foundation of the v2 base — which achieved 87.43% MMLU-Pro and 75.25% SWE-bench Verified — and further specializes it for agentic code generation, structured tool calling, debugging, and instruction-following in developer workflows. The model is designed to excel at repository-level coding tasks, multi-turn tool orchestration, and complex logical reasoning under realistic agent environments.
🧩 Agentic Coding
Optimized for repository-level coding, debugging, patch generation, and structured multi-step development workflows.
🛠️ Tool Calling
Learns from real agent trajectories with tool definitions, tool calls, and environment feedback for robust multi-turn execution.
...
Repository: localaiLicense: apache-2.0
kimi-k2.7-code
## 1. Model Introduction
Kimi K2.7 Code is a coding-focused agentic model built upon Kimi K2.6. With substantial improvements on real-world long-horizon coding tasks, it strengthens end-to-end task completion across complex software engineering workflows while improving token efficiency, reducing thinking-token usage by approximately 30% compared with Kimi K2.6.
## 2. Model Summary
## 3. Evaluation Results
Benchmark
Kimi K2.6
Kimi K2.7 Code
GPT-5.5
Claude Opus 4.8
Coding
Kimi Code Bench v2
50.9
62.0
69.0
67.4
Program Bench
48.3
53.6
69.1
63.8
MLS Bench Lite
26.7
35.1
35.5
42.8
Agentic
Kimi Claw 24/7 Bench
42.9
46.9
52.8
50.4
MCP Atlas
69.4
76.0
79.4
81.3
MCP Mark Verified
72.8
81.1
92.9
76.4
Footnotes
...
Repository: localaiLicense: other
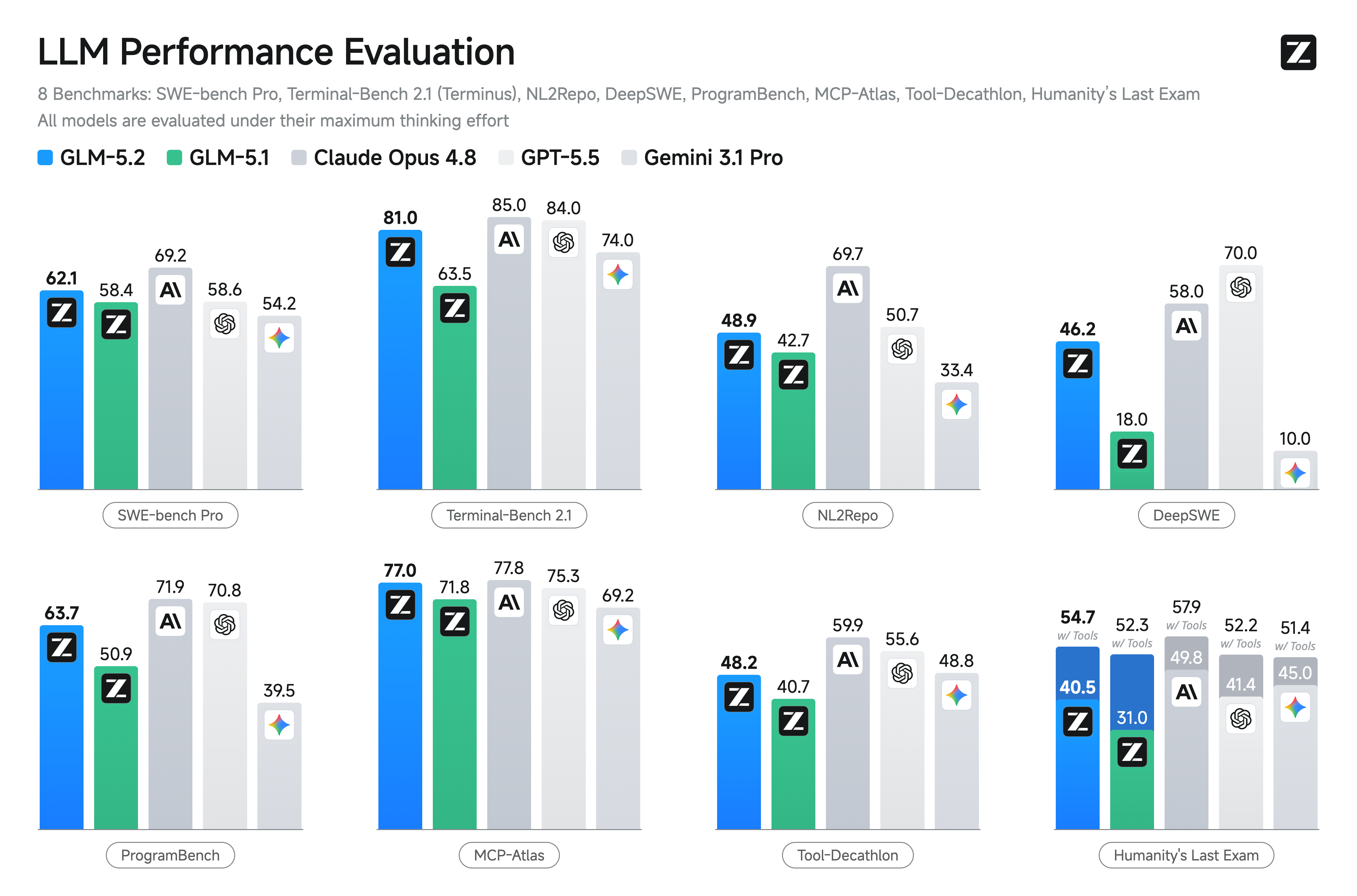
glm-5.2
# GLM-5.2
👋 Join our WeChat or Discord community.
📖 Check out the GLM-5.2 blog and GLM-5 Technical report.
📍 Use GLM-5.2 API services on Z.ai API Platform.
🔜 Try GLM-5.2 here.
[Paper]
[GitHub]
## Introduction
We're introducing GLM-5.2, our latest flagship model for long-horizon tasks. It marks a substantial leap in long-horizon task capability over its predecessor GLM-5.1 and, for the first time, delivers that capability on a **solid 1M-token context**. GLM-5.2's new capabilities include:
- **Solid 1M Context:** A solid 1M-token context that stably sustains long-horizon work
- **Advanced Coding with Flexible Effort**: Stronger coding capabilities with multiple thinking effort levels to balance performance and latency
- **Improved Architecture**: We propose IndexShare, which reuses the same indexer across every four sparse attention layers, reducing per-token FLOPs by 2.9× at a 1M context length. We also improve GLM-5.2’s MTP layer for speculative decoding, increasing the acceptance length by up to 20%
- **Pure Open**: An MIT open-source license — no regional limits, technical access without borders
## Benchmark
## Serve GLM-5.2 Locally
...
Repository: localaiLicense: mit
qwopus3.6-27b-coder-mtp-nvfp4
🪐 Qwopus-3.6-27B-Coder
Coder SFT Release
Agentic Coding & Tool-Use Reasoning Model Fine-Tuned on Qwopus3.6-27B-v2
🧬 Trace Inversion & Negentropy
🧠 27B Dense Model
⚡ Agentic Coding
🛠️ Tool Calling & Agent
🏆 SWE-bench Verified: 67.0% (off-thinking)
💡 What is Qwopus-3.6-27B-Coder?
🪐 Qwopus-3.6-27B-Coder is a reasoning-enhanced agentic coding model built on top of Qwopus3.6-27B-v2. It inherits the powerful reasoning foundation of the v2 base — which achieved 87.43% MMLU-Pro (300ex) and 75.25% SWE-bench Verified — and further specializes it for agentic code generation, structured tool calling, debugging, and instruction-following in developer workflows. The model is designed to excel at repository-level coding tasks, multi-turn tool orchestration, and complex logical reasoning under realistic agent environments.
🧩 Agentic Coding
Optimized for repository-level coding, debugging, patch generation, and structured multi-step development workflows.
🛠️ Tool Calling
Learns from real agent trajectories with tool definitions, tool calls, and environment feedback for robust multi-turn execution.
...
Repository: localai

gemma-4-12b-agentic-fable5-composer2.5-v2-3.5x-tau2
Hugging Face |
GitHub |
Launch Blog |
Documentation
License: Apache 2.0 | Authors: Google DeepMind
> [!Note]
> This model card is for the Gemma 4 12B Unified model, which is part of the Gemma 4 family of open models. Built with the same multimodal functionality as Gemma 4 E2B and E4B (text, audio, image, and video inputs), it brings native audio and vision understanding directly to local environments without the need for separate encoders. This unified approach to multimodality makes the model encoder-free, offering a deployment size that is perfect for consumer devices and streamlined local execution.
Gemma is a family of open models built by Google DeepMind. Gemma 4 models are multimodal, handling text and image input (with audio supported on E2B, E4B, and 12B) and generating text output. This release includes open-weights models in both pre-trained and instruction-tuned variants. Gemma 4 features a context window of up to 256K tokens and maintains multilingual support in over 140 languages.
...
Repository: localaiLicense: apache-2.0
gemma-4-12b-coder-fable5-composer2.5-v1
Hugging Face |
GitHub |
Launch Blog |
Documentation
License: Apache 2.0 | Authors: Google DeepMind
> [!Note]
> This model card is for the Gemma 4 12B Unified model, which is part of the Gemma 4 family of open models. Built with the same multimodal functionality as Gemma 4 E2B and E4B (text, audio, image, and video inputs), it brings native audio and vision understanding directly to local environments without the need for separate encoders. This unified approach to multimodality makes the model encoder-free, offering a deployment size that is perfect for consumer devices and streamlined local execution.
Gemma is a family of open models built by Google DeepMind. Gemma 4 models are multimodal, handling text and image input (with audio supported on E2B, E4B, and 12B) and generating text output. This release includes open-weights models in both pre-trained and instruction-tuned variants. Gemma 4 features a context window of up to 256K tokens and maintains multilingual support in over 140 languages.
...
Repository: localaiLicense: gemma
dark-scarlett-v0.3-26b-a4b
Hugging Face |
GitHub |
Launch Blog |
Documentation
License: Apache 2.0 | Authors: Google DeepMind
Gemma is a family of open models built by Google DeepMind. Gemma 4 models are multimodal, handling text and image input (with audio supported on small models) and generating text output. This release includes open-weights models in both pre-trained and instruction-tuned variants. Gemma 4 features a context window of up to 256K tokens and maintains multilingual support in over 140 languages.
Featuring both Dense and Mixture-of-Experts (MoE) architectures, Gemma 4 is well-suited for tasks like text generation, coding, and reasoning. The models are available in four distinct sizes: **E2B**, **E4B**, **26B A4B**, and **31B**. Their diverse sizes make them deployable in environments ranging from high-end phones to laptops and servers, democratizing access to state-of-the-art AI.
Gemma 4 introduces key **capability and architectural advancements**:
* **Reasoning** – All models in the family are designed as highly capable reasoners, with configurable thinking modes.
...
Repository: localaiLicense: apache-2.0

qwen3.6-40b-claude-4.6-opus-deckard-heretic-uncensored-thinking-neo-code-di-imatrix-max
The Qwen 3.5 version (also 40B) got 181 likes+ This version uses the new Qwen 3.6 27B arch (which exceeds even Qwen's own 398B model).
WARNING: This model has character and intelligence. It will take no prisoners. It will give no quarter. Uncensored,
Unfiltered and boldly confident. Not even remotely "SFW", if you ask it for NSFW content. And it is wickedly smart too - exceeding the base model in 6 out of 7 benchmarks.
Qwen3.6-40B-Claude-4.6-Opus-Deckard-Heretic-Uncensored-Thinking
40 billion parameters (dense, not moe) expanded from 27B Qwen 3.6, then trained on Claude 4.6 Opus High Reasoning dataset via Unsloth on local hardware... but there
is much more to the story - in comes DECKARD.
96 layers, 1275 Tensors. (50% more than base model of 27B)
Features variable length reasoning ; less complex = shorter, longer for more complex.
Model performance has increased dramatically. And it has character too.
A lot of character.
No censorship, no nanny. (via Heretic)
And it is very, very smart.
...
Repository: localaiLicense: apache-2.0
supergemma4-26b-uncensored-v2
Hugging Face |
GitHub |
Launch Blog |
Documentation
License: Apache 2.0 | Authors: Google DeepMind
Gemma is a family of open models built by Google DeepMind. Gemma 4 models are multimodal, handling text and image input (with audio supported on small models) and generating text output. This release includes open-weights models in both pre-trained and instruction-tuned variants. Gemma 4 features a context window of up to 256K tokens and maintains multilingual support in over 140 languages.
Featuring both Dense and Mixture-of-Experts (MoE) architectures, Gemma 4 is well-suited for tasks like text generation, coding, and reasoning. The models are available in four distinct sizes: **E2B**, **E4B**, **26B A4B**, and **31B**. Their diverse sizes make them deployable in environments ranging from high-end phones to laptops and servers, democratizing access to state-of-the-art AI.
Gemma 4 introduces key **capability and architectural advancements**:
* **Reasoning** – All models in the family are designed as highly capable reasoners, with configurable thinking modes.
...
Repository: localaiLicense: gemma

qwen_qwen3-next-80b-a3b-thinking
Repository: localaiLicense: apache-2.0

mistral-nemo-instruct-2407-12b-thinking-m-claude-opus-high-reasoning-i1
The model described in this repository is the **Mistral-Nemo-Instruct-2407-12B** (12 billion parameters), a large language model optimized for instruction tuning and high-level reasoning tasks. It is a **quantized version** of the original model, compressed for efficiency while retaining key capabilities. The model is designed to generate human-like text, perform complex reasoning, and support multi-modal tasks, making it suitable for applications requiring strong language understanding and output.
Repository: localai

qwen3-vl-30b-a3b-instruct
Meet Qwen3-VL — the most powerful vision-language model in the Qwen series to date.
This generation delivers comprehensive upgrades across the board: superior text understanding & generation, deeper visual perception & reasoning, extended context length, enhanced spatial and video dynamics comprehension, and stronger agent interaction capabilities.
Available in Dense and MoE architectures that scale from edge to cloud, with Instruct and reasoning‑enhanced Thinking editions for flexible, on-demand deployment.
#### Key Enhancements:
* **Visual Agent**: Operates PC/mobile GUIs—recognizes elements, understands functions, invokes tools, completes tasks.
* **Visual Coding Boost**: Generates Draw.io/HTML/CSS/JS from images/videos.
* **Advanced Spatial Perception**: Judges object positions, viewpoints, and occlusions; provides stronger 2D grounding and enables 3D grounding for spatial reasoning and embodied AI.
* **Long Context & Video Understanding**: Native 256K context, expandable to 1M; handles books and hours-long video with full recall and second-level indexing.
* **Enhanced Multimodal Reasoning**: Excels in STEM/Math—causal analysis and logical, evidence-based answers.
* **Upgraded Visual Recognition**: Broader, higher-quality pretraining is able to “recognize everything”—celebrities, anime, products, landmarks, flora/fauna, etc.
* **Expanded OCR**: Supports 32 languages (up from 19); robust in low light, blur, and tilt; better with rare/ancient characters and jargon; improved long-document structure parsing.
* **Text Understanding on par with pure LLMs**: Seamless text–vision fusion for lossless, unified comprehension.
#### Model Architecture Updates:
1. **Interleaved-MRoPE**: Full‑frequency allocation over time, width, and height via robust positional embeddings, enhancing long‑horizon video reasoning.
2. **DeepStack**: Fuses multi‑level ViT features to capture fine-grained details and sharpen image–text alignment.
3. **Text–Timestamp Alignment:** Moves beyond T‑RoPE to precise, timestamp‑grounded event localization for stronger video temporal modeling.
This is the weight repository for Qwen3-VL-30B-A3B-Instruct.
Repository: localaiLicense: apache-2.0
qwen3-vl-30b-a3b-thinking
Qwen3-VL-30B-A3B-Thinking is a 30B parameter model that is thinking.
Repository: localaiLicense: apache-2.0
qwen3-vl-32b-instruct
Qwen3-VL-32B-Instruct is the 32B parameter model of the Qwen3-VL series.
Repository: localaiLicense: apache-2.0
qwen3-vl-4b-thinking
Qwen3-VL-4B-Thinking is the 4B parameter model of the Qwen3-VL series that is thinking.
Repository: localaiLicense: apache-2.0
qwen3-vl-2b-thinking
Qwen3-VL-2B-Thinking is the 2B parameter model of the Qwen3-VL series that is thinking.
Repository: localaiLicense: apache-2.0
qwen3-vl-2b-instruct
Qwen3-VL-2B-Instruct is the 2B parameter model of the Qwen3-VL series.
Repository: localaiLicense: apache-2.0
qwen3-vl-8b-thinking
Qwen3-VL-8B-Thinking is the 8B parameter model of the Qwen3-VL series that is thinking.
Uses recommended default parameters according to Unsloth documentation for Qwen 3 VL.
Repository: localaiLicense: apache-2.0
qwen3-omni-30b-a3b-thinking
Qwen3-Omni-30B-A3B-Thinking is the reasoning-enhanced variant of Qwen3-Omni, a natively end-to-end multilingual omni-modal foundation model. It processes text, images, and audio and produces chain-of-thought reasoning before the final answer. This GGUF build runs on llama.cpp with the bundled mmproj.
Repository: localaiLicense: apache-2.0

baidu_ernie-4.5-21b-a3b-thinking
Over the past three months, we have continued to scale the thinking capability of ERNIE-4.5-21B-A3B, improving both the quality and depth of reasoning, thereby advancing the competitiveness of ERNIE lightweight models in complex reasoning tasks. We are pleased to introduce ERNIE-4.5-21B-A3B-Thinking, featuring the following key enhancements:
Significantly improved performance on reasoning tasks, including logical reasoning, mathematics, science, coding, text generation, and academic benchmarks that typically require human expertise.
Efficient tool usage capabilities.
Enhanced 128K long-context understanding capabilities.
Note: This version has an increased thinking length. We strongly recommend its use in highly complex reasoning tasks. ERNIE-4.5-21B-A3B-Thinking is a text MoE post-trained model, with 21B total parameters and 3B activated parameters for each token.
Repository: localaiLicense: apache-2.0

liquidai_lfm2-1.2b-tool
Based on LFM2-1.2B, LFM2-1.2B-Tool is designed for concise and precise tool calling. The key challenge was designing a non-thinking model that outperforms similarly sized thinking models for tool use.
Use cases:
Mobile and edge devices requiring instant API calls, database queries, or system integrations without cloud dependency.
Real-time assistants in cars, IoT devices, or customer support, where response latency is critical.
Resource-constrained environments like embedded systems or battery-powered devices needing efficient tool execution.
Repository: localaiLicense: lfm1.0
Page 1